
Stefaan Verhaulst, GovLab Blog, 2 Aug 2017
At a time of open and big data, data-led and evidence-based policy making has great potential to improve problem solving but will have limited, if not harmful, effects if the underlying components are riddled with bad data.
Why should we care about bad data? What do we mean by bad data? And what are the determining factors contributing to bad data that if understood and addressed could prevent or tackle bad data? These questions were the subject of my short presentation during a recent webinar on Bad Data: The Hobgoblin of Effective Government, hosted by the American Society for Public Administration and moderated by Richard Greene (Partner, Barrett and Greene Inc.). Other panelists included Ben Ward (Manager, Information Technology Audits Unit, California State Auditor’s Office) and Katherine Barrett (Partner, Barrett and Greene Inc.). The webinar was a follow-up to the excellent Special Issue of Governing on Bad Data written by Richard and Katherine.
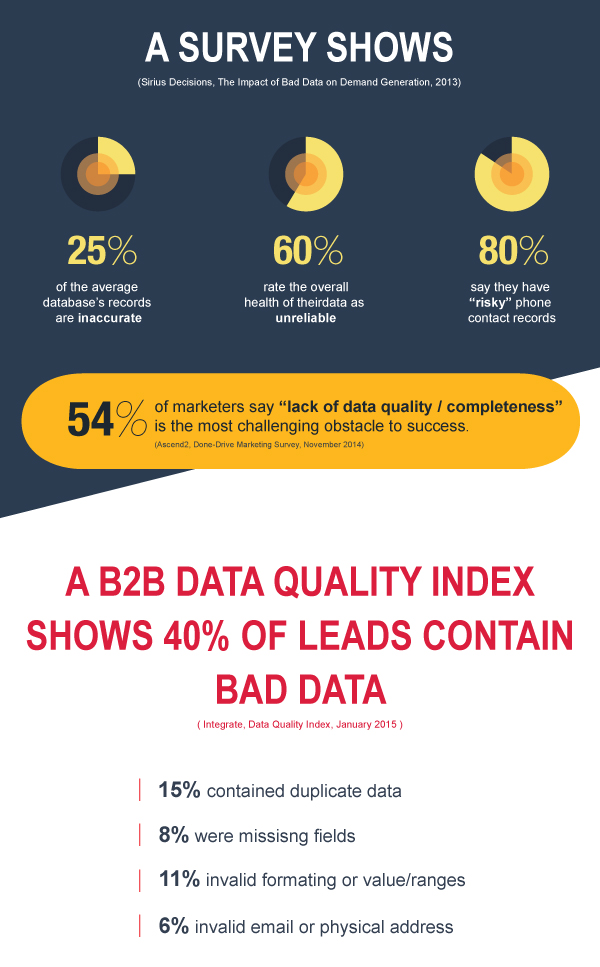
The quality of data impacts the quality of decisions made using that data.
As governance practices around the world move closer to a standard of data-driven policy making, curbing practices that can lead to bad data is critical. Not only does bad data threaten the reliability of data-driven policy making, it has myriad other ill effects – from creating civil liberties concerns, to undermining trust in government, to increased costs, waste and inefficiencies. For instance, according to CrowdFlower, data scientists spend nearly two-thirds of their time cleaning and organizing bad data instead of analyzing and creating insights.
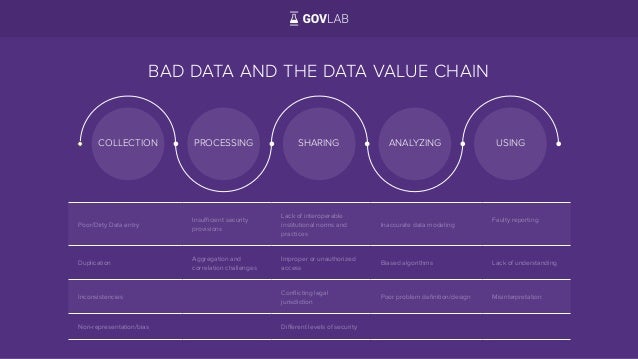
Bad data occurs across the Data Value Chain

Bad Data and The Data Value Chain developed by Stefaan Verhulst, The GovLab.
Bad data can be the result of many different information manipulation practices. As such, understanding thedifferent manifestations of bad data across the Data Value Chain can help us address current issues with bad data, and prevent future challenges. Precautions taken at the Collection, Processing, Sharing, Analyzing, and Using phases of the data value chain to address issues such as bad data entry, poor modeling or misinterpretation can markedly increase the quality, accuracy, and ultimately the utility of open data.
These bad data manifestations don’t occur in a vacuum, but result from various factors such as:
The need for a culture of data quality
The webinar’s main objective was to draw attention to the potentially serious problem posed by bad data. Although not always considered a high-priority topic, it nonetheless merits urgent attention as we are adopting data-driven policy making or releasing more open data. Bad data lowers trust, creates liabilities and civil liberties concerns, increases costs, and can in some cases produce serious harm or even loss of life.
Being aware of and addressing the determining factors listed above would provide for progress yet represent only a starting point. In many ways, efforts to tackle bad data are still in their infancy. As data volumes and our society’s reliance on data increase, so too will the impacts of the problem. It is likely, too, that greater awareness will lead to new strategies for managing and reducing bad data.
Those strategies may include new technical tools, but they will almost certainly involve new policies, norms and expectations, too. The coming years are likely to witness greater attention and action by governments regarding the problem of bad data. To be successful, those actions need to be the result of a conversation across sectors and industries. My presentation and the webinar can be seen as input to the still-developing conversation towards the creation of a “data quality culture.”
Source: http://thegovlab.org/why-we-should-care-about-bad-data/

{kind=link}
{kind=link}